Is your CMS SEO-friendly? Part 2
When you have to choose the right content management system (CMS) there are a lot of things to consider. And many different stakeholders will have their own requirements. One thing that should always be considered is the answer asked here: How SEO-friendly is the CMS?
Last week we took a look at the 4 website performance features that you need from your CMS. Today we're going to look at the next topic: technical SEO features.
18 SEO-friendly features you should look for in a CMS
Because there's no "SEO-friendly" stamp, I decided to make my own list of features that I believe an SEO-friendly content management system should have. In total, I found 18 features across 3 main categories: Website performance features, technical SEO features and On-page SEO features.
Website performance features
Your CMS should be built for performance and enable you to have a fast website that can handle high traffic loads. This is important regardless of SEO, but with the introduction of Web Vitals and Core Web Vitals from Google, it’s clear that it will have a big impact on your SEO as well. So if your website isn’t performing well, you’re off to a bad start in your quest for page 1 on the search engine results pages (SERP).
Important features for all websites
- #1 - Responsive design
- #2 - Page speed
- #3 - HTTPS support
- #4 - Tracking scripts
We took a closer look at these in part 1 of this blog series.
Technical SEO features
There’s a lot more going on "under the hood" than what meets the eye. That’s why this category has the longest feature list. While a lot of these things might be seen as obvious, it’s important to make sure that they are part of your CMS feature set. If not, you’ll most likely experience just how big of a difference they can make for your SEO (in a bad way).
Important features for technical SEO
We'll be taking a closer look at these 10 features today.
On-page SEO features
Last, but not least, we have the on-page SEO features that get most of the spotlight. These are core features that you should have when optimizing your content for SEO. One common thing with these features is that they should give you the flexibility to use them as you see fit. If you're restricted on any of these features it can hurt your scalability down the line.
Important features for On-page SEO
- #15 - Title tags and meta descriptions
- #16 - Content headers (H1, H2, etc.)
- #17 - Image ALT text
- #18 - Page URL
We'll take a closer look at these 4 features in part 3 of this blog series.
Let's get started, shall we?
Technical SEO features
Are you surprised that 10 out of the 18 SEO-friendly features on this list are in this category?
That’s probably a good thing because it means that you’ve come to expect many of these features as a core part of any CMS.
Luckily, many systems do provide most (if not all) of these features. It’s nonetheless important to check before choosing a CMS, as many of these can make-or-break your SEO efforts.
#5 - Crawlability and indexability of your content
Did you ever stop to make sure that search engine crawlers like Googlebot can crawl all of your pages and index its content properly?
Probably not. It’s not really on top of many SEO checklists out there. That's a shame though, as I would argue it should be at the top of your list for any technical SEO audit you do. It's that important.
Admittedly, issues with crawlability and indexability are rare and for most websites (and content management systems) it’s not an issue. But when there are issues, these can result in devastating losses in search traffic and rankings.
That’s why you should make sure that your website follows best practices on how it makes your content available to crawlers. Can crawlers access your website content? And when they access your website, can they crawl the content on your pages, so it’s properly added to the search index?
The best way to answer those questions is to first look at whether crawlers can access your site (crawlability) and next to look at how your content is made available to web crawlers (indexability).
Crawlability
An easy way to test crawlability is to use Google Search Console and test out your URLs. If they are blocked from being crawled, you’ll get an error back like the one below:
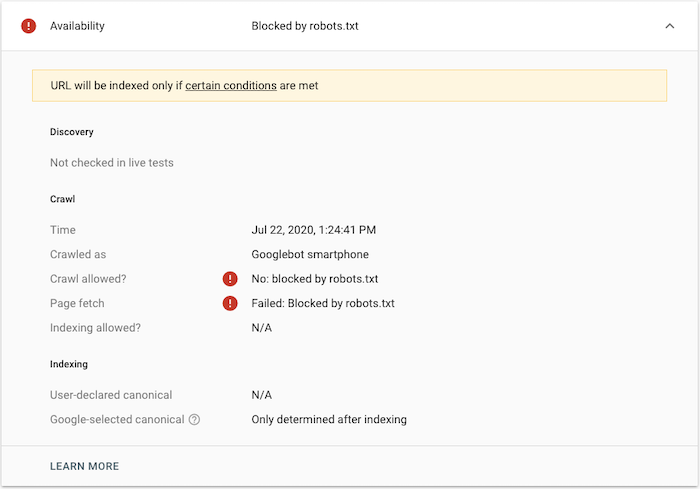
If your page is blocked (and shouldn’t be) you should have a look at your robots.txt file (see next feature for more details). And if the issue is something different, well, then you have some troubleshooting to do.
Indexability
Once you’ve ensured that Google can crawl your website content, it’s important to look at 2 things:
- If your page is getting indexed
- And how much of your content it actually puts into the index
Most SEO audits focus on whether or not a page is in the index, but not if Googlebot crawled all of the page or only parts of it. To understand why this is so important, it’s good to know how Google serves its search results.
For that, you should look at this video by Google (yes, it’s old, but still relevant since the fundamentals on crawling and indexing have not changed).
So how do you ensure that all of your content is indexed correctly?
You make sure that the content is served in a way that is easy for crawlers to process.
This might sound very technical, but it really isn’t. Take a look at the source code of your page; can you find your content if you search for it?
In most cases, your content will be served through clean HTML and will be present in the source code. If that’s the case for you, then you should be good to go.
If your content can’t be found or is served through Flash, frames or something other than HTML, then you might be in trouble. To check if Google can actually crawl and index the content of your page, you should test it. Here are 2 quick ways to do so:
- Use Google Search Console’s “Inspect URL” feature and test the live URL of the page. Now you’re able to see a screenshot of what was crawled as well as the HTML that Google found. If your content is found in the HTML that Google returned here, then it’ll be in the index as well.
- Make a phrase match search on Google by copying a paragraph from your page and put it in quotation marks in a Google search (ie. “pasted content paragraph here”). If your site does not appear in the results, then your site could have indexability issues hurting your SEO.
So what about serving content through JavaScript - is that bad?
You might have heard that Google can’t crawl content if it’s added through JavaScript. That is no longer the case.
That being said, you should be cautious and test more often if your website relies on JavaScript for serving content. As you can see in the figure below, crawling and indexing JavaScript content is done; but it requires an extra step for Googlebot: rendering.
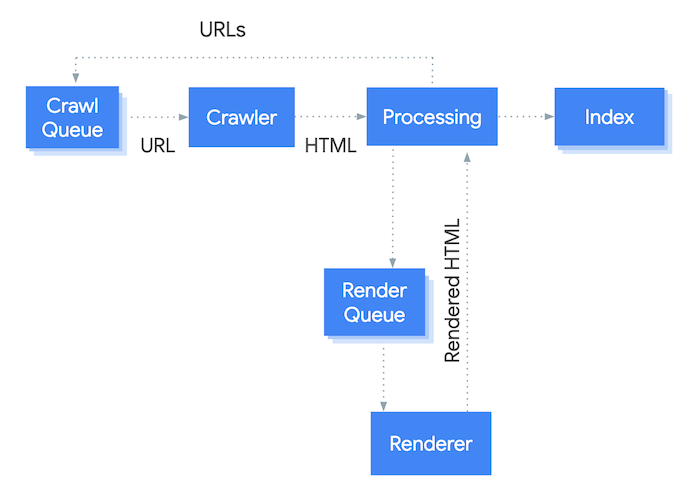
So if your website is relying on JavaScript content you might have to wait longer before Google updates the content they have in their index, as it takes them longer to process. It also requires additional resources, which might further limit your crawl budget.
On umbraco.com we do use JavaScript to serve some of our content, so the above is not to scare you away from using it. It's mostly a word of caution so you're sure to check that the content is rendered properly and you're not losing SEO-value on your pages.
#6 - Robots.txt file

Let’s dive a bit deeper into crawlability and one of the main ways to control it: the robots.txt file.
A robots.txt file is a simple text file that is put in the root of your site (ie. domain.com/robots.txt) that instructs crawlers and bots on what they’re allowed to crawl on your website.
This is a very important feature for larger websites with a lot of content that want to optimize their crawl budget. By putting crawling instructions in robots.txt you can block Googlebot from spending resources on crawling irrelevant URLs. Instead, it’ll be able to use your crawl budget on the pages you want to have in the index instead. This ensures that new updates to your important pages will be indexed faster.
Another great use for the robots.txt file is when you're developing a new website, that is not ready to be indexed by Google yet. If your CMS allows you to edit the robots.txt file, you can disallow all web crawlers from ever crawling your site. That way you can avoid future problems like having the wrong domain name showing up in the search results and the potential duplicate content issues that can bring.
#7 - Noindex and nofollow settings

What if you want Google to crawl a page, but keep it out of its index?
If that’s the case, you can do it by telling Google about it. The same goes for pages with links that you do not want to attribute any value, in which case you’d want to use the nofollow attribute.
Being able to edit these give you a great deal of flexibility and allows you to keep pages out of the search index that shouldn’t be in there. This can help keep unwanted pages such as campaign pages and thin content pages out of the index.
It can also help alleviate duplicate content issues, although that’s often better handled using canonical tags (see next feature).
To add your noindex and/or nofollow directives to a page, you'll need the following code to be added to the <head> section of the page code:
<meta name="robots" content="setting here">
Please note that the "nofollow" directive will result in all links on a page to be counted as nofollow links. If you want to control it for each link on the page, you'll need to use the rel="nofollow" link attribute.

What do you do if multiple pages on your site are duplicates or close duplicates?
You use the canonical tag.
This feature enables you to tell web crawlers if a page is similar to another page and to point at which page is the original. This helps you avoid duplicate content issues and ensures that Google shows the original page in the search results instead of any of the other duplicates.
If your CMS has this feature you will typically be allowed to set it on a page level, so you can point from the duplicate page to the original page. Technically this is done by adding <link rel="canonical" href="example.com/original-page" /> to the <head> of the duplicate page. This will tell crawlers that the original page is found on that URL and that this one should not be shown in search results.
#9 - XML sitemaps

To help Google crawl and index your website, it’s a best practice to have an XML sitemap. This is another small file that should be added to the root of your site like the robots.txt file. The file consists of all pages on your website in XML format and can be accompanied with other attributes (such as change frequency, priority and a date for the last update).
What is a sitemap? Here's an in-depth look at sitemaps.
Having a sitemap and submitting it to Google (and other search engines) is important, as it clearly shows Google a list of all URLs on your website. It will also alert Google to new URLs published on your site and can make Googlebot come by to crawl and index the newly published content.
#10 - URL structure

Your URL structure should be following the same hierarchy as your content to make your website structured easy to understand for users and crawlers alike. The URL of a page is even a ranking factor that Google uses to understand, index and rank your content.
So what does a good URL structure look like? Ideally, you want 3 things from your URL structure:
- It should be descriptive enough for users and crawlers to understand what the page is about
- It should be readable by humans
- It should be as close to your front page as possible
To the first two points, you should always aim to have readable and understandable URLs. That way they can hint to users and crawlers how this specific page fits into your overall hierarchy. That means having actual words in your URL and not just a page ID or something unreadable.
Let’s take an example: umbraco.com/products/umbraco-cms/umbraco-8/
What can we say about this URL just from looking at it?
First off, we have /products/ which tells us that the page is about one of the Umbraco products.
Next, /umbraco-cms/gives us the product category: the CMS.
Lastly /umbraco-8/ tells us that the page is about the latest version of Umbraco; Umbraco 8.
This is a great structure, as it makes it easily understandable, and each part of the URL is descriptive so you will - from the URL alone - be able to know what the content is about.
To the third point in our list, we can see that the URL in our example is 3 clicks away from the front page of our site. This is more than fine and a typical rule of thumb is that your most important pages should never be more than 4 clicks away.
All of this might seem very intuitive and a standard feature in most content management systems out there. And luckily it is, but there are exceptions.
Some of these content management systems add extra paths to your URLs automatically. This can cause issues when you’re working with SEO as it will effectively push all underlying content further down in your hierarchy and further away from your front page.
Ideally, you’ll want a CMS that gives you a simple URL structure from the start - without adding extra paths automatically - and one in which you can change the structure if you want to. This counts both for the overall structure as well as for the individual pages (more on this in part 3 of this series).
#11 - URL redirect management
A website is never static and the same can be said for your website content.
What happens if you want to move a page to a different part of your site, or change the name of it? Then the URL will most likely change as well.
This happens all the time, but can cause issues for your SEO if no redirect is added.
What happens to the internal and external links pointing to the old URL of the page? If your CMS doesn’t have any URL redirect management all links pointing to the old URL will now lead to a 404 status code: page not found. If that happens there’s a very good chance that the page will lose its visibility in the search results and that sweet organic traffic you worked so hard for is now lost.
So why does that happen? If you look at it from a technical standpoint, it makes sense. When you create a new page and the page is crawled by Googlebot, they have no indication as to whether this is a new page or if it already existed somewhere else. So they treat it as a new page and as such it loses all previous value that it had.
The solution to all of these problems: URL redirects.
If your CMS offers this feature you’ll be able to add a 301 permanent or 302 temporary redirects to tell users and crawlers alike that the page is now found somewhere else.
This gives a great user experience as they’re redirected automatically to the right page. Web crawlers will also understand the connection and transfer the link value from the old URL to the new, so your losses will be minimal (if any).
What if a page is removed, instead of moved?
Then it might still make sense to use redirects. Redirecting the removed page to something similar will help you keep the value from any external links pointing to the removed page.
#12 - Schema markup
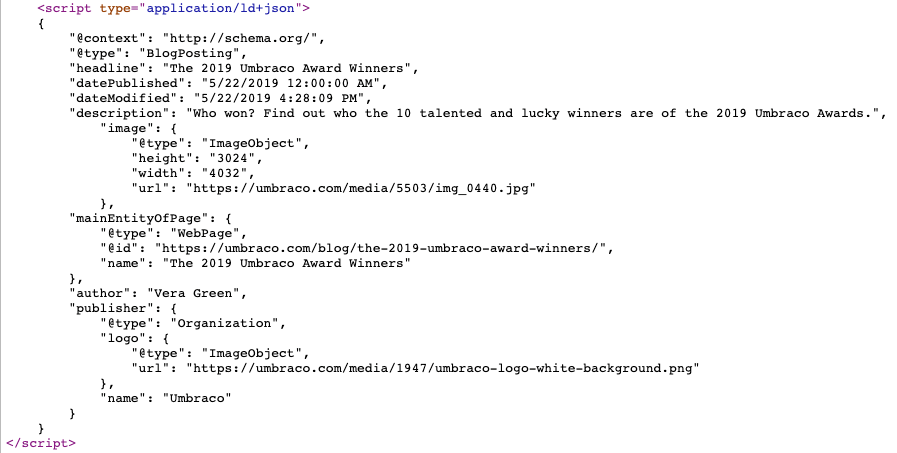
Schema markup is by no means a new development in SEO. For years now, marketers and developers have been using it to help search engines make sense of their content. It is essentially a bit of code which helps search engines understand the content of a page. The code must be structured in a certain way, where JSON-LD is the recommended format.
Having schema markup on your page means that search engines can display additional information about your content within the search results which helps to improve your click-through rate. It also helps your content be shown in rich results such as the “Featured snippet” or “FAQ rich results”, which will help your website get more real estate in the search results.
Schema.org is a collaborative project between Google, Bing and Yahoo. As such, Schema that is added to your site will be readable across all of the main search engines.
There are hundreds of markup types – from restaurants, recipes and movies, right down to the very niche. If you have any data on your website, there’s a good chance that it’s going to have an associated Schema type.
To implement schema markup on your website, you’ll need access to edit the code of your pages. As long as that’s possible in your CMS, you should be able to implement various schema types. Alternatively, you might find packages that can handle it for you automatically.
While some schema types are very specific, there are some more generic ones that any website can implement. Here's a list of some of the broader types that most can use (and that we use on umbraco.com as well):

If you’re going to have multiple languages on your website, you’ll need to get familiar with hreflang tags. These tags are used to tell search engines which language variants you have for every single page on your website.
The advantage of using it is that search engines will be able to know which language variant to show in the search results depending on the user’s language and country.
Let's say someone is searching from Spain and doesn't speak any English - wouldn't it be nice if they would then be sent directly to the Spanish version of your website? It sure would - and that's what you get if you've implemented hreflang tags.
It also helps you tie together your content so you keep all of your content organized and structured for Google to understand: even across languages.
To implement hreflang tags you'll need to add a few lines of code to the <head> of your site (either manually or by using a built-in feature or extension). Here's an example of how it would look for a page that exists in English, Danish and Spanish:
<link rel="alternate" hreflang="en" href="https://umbraco.com/en/english-version/" />
<link rel="alternate" hreflang="da" href="https://umbraco.com/da/danish-version/" />
<link rel="alternate" hreflang="es" href="https://umbraco.com/es/spanish-version/" />
<link rel="alternate" hreflang="x-default" href="https://umbraco.com/en/english-version/" />
#14 - AMP support

The mobile-first approach from Google is well known. And it’s not going to change any time soon.
One of the things they introduced back in 2015 was AMP - accelerated mobile pages. These pages are lightweight versions of your normal pages that can load on mobile devices a lot faster than regular pages.
This is a great way to create a great user experience with a blazing fast page that loads almost instantly on mobile devices. And with the mobile-first index and Core Web Vitals coming up, it's certainly a thing to consider implementing to score higher on those two factors.
There’s just one tiny problem though: it can be really tricky to implement and is rarely an out-of-the-box feature for a CMS.
The reason is that the AMP format has to follow a strict set of guidelines on how the page is built. It’s still built with HTML, CSS and JavaScript, but all three have to be stripped down and streamlined. So if your website is customized in any way, it's very hard to have a generic out-of-the-box feature that just works.
For SEO, it’s a great feature to have in the fight for more mobile search visitors though. Due to the fast load times and great user experience, it’ll often be valued very highly by Google when choosing which search results to serve a user on a mobile device.
Due to the restrictions on the AMP pages, it's hard (if not to say impossible) to have AMP-versions for all pages on your site. That's especially true if you're running an ecommerce site that relies heavily on JavaScript functionality.
If you're looking to implement AMP, you should instead aim to make AMP-versions for some sections of your content and expand as you go. A great place to start is with blog posts. These typically consist of simple elements and do not require advanced functionality to give a great user experience.
Is your CMS SEO-friendly?
Last week we took the first 4 features, now we've taken 10 more - we're almost there! So are we getting any closer to an answer? I'd say so.
If you can set a nice checkmark next to all of the 14 features so far, there's a very good chance that your CMS is SEO-friendly; at least by the standards that I've set so far in this blog series.
How is Umbraco doing so far? If you haven't already, you can jump on over and read how SEO-friendly Umbraco is when looking at all 18 features on my list.
How SEO-friendly is Umbraco?
Written byLars Skjold Iversen
Posted: Tuesday 14 July 2020